How AI Assistants Decide Which Brands to Recommend
AI assistants do not browse the web and pick favorites. They synthesize from sources — and brands that appear in those sources get named. Here is how that process works.
When a customer asks ChatGPT to recommend a tool in your category and your brand does not appear, the problem is not that the AI dislikes you. It is that the systems generating that answer did not find enough reliable, consistent, corroborated information about you to include you confidently. AI assistants synthesize from sources. Brands that appear in those sources get named. Understanding how that synthesis works is the prerequisite for doing anything about it.
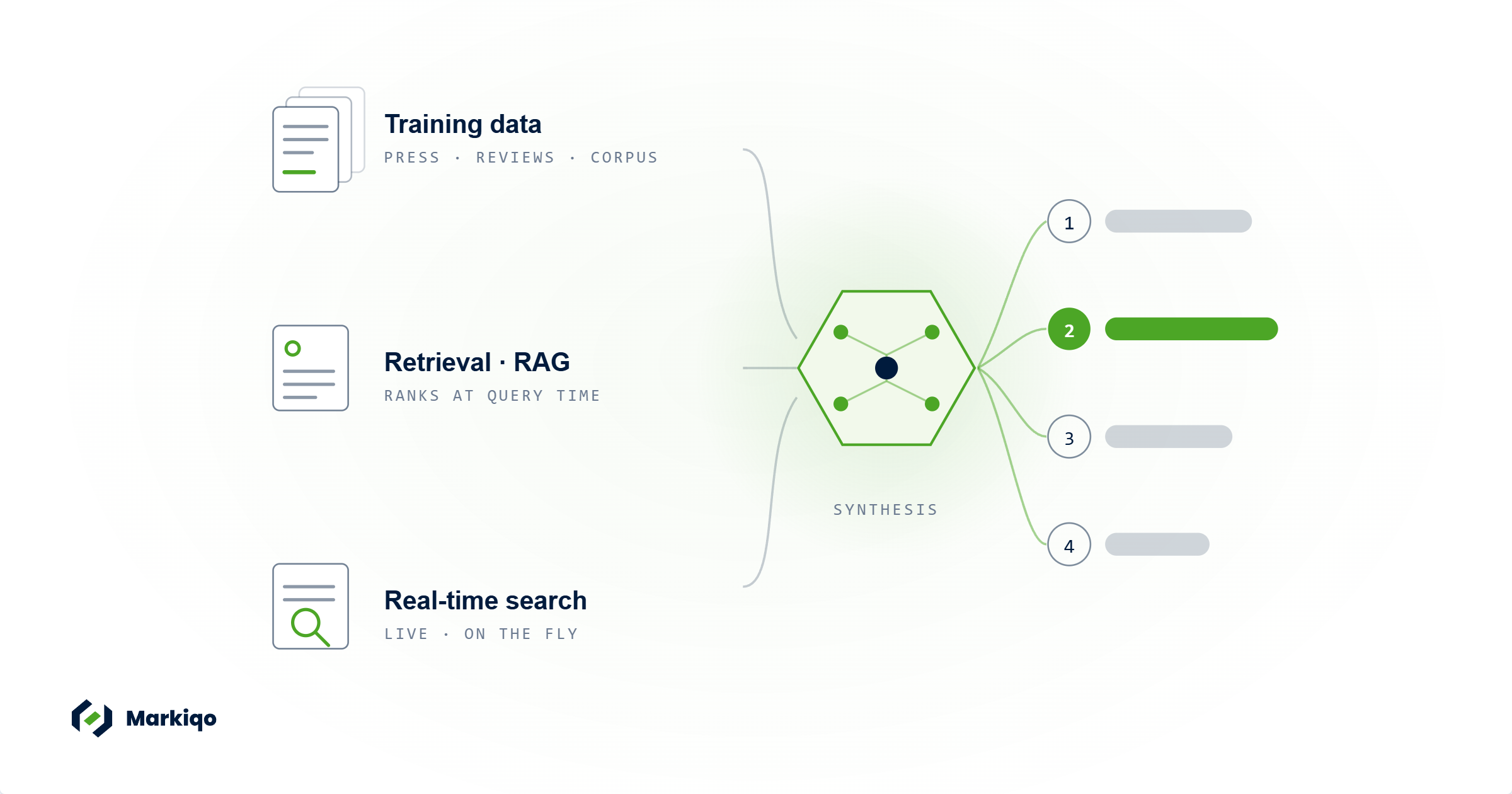
The three mechanisms
Every major AI assistant uses some combination of three mechanisms to generate answers.
Training data. Large language models are trained on massive text corpora assembled before a cutoff date. Everything the model knows about your brand at baseline comes from this corpus — articles, reviews, analyst reports, forum discussions, press coverage. Volume matters. Authority matters. A brand with thin third-party coverage is represented weakly regardless of how polished its own website is.
Retrieval-augmented generation (RAG). Many AI assistants pull live content at query time to supplement their training. Perplexity is built almost entirely on this model. ChatGPT with search and Bing Copilot use it heavily. What gets retrieved depends on what ranks for the relevant query. This is where traditional search authority and AI visibility overlap most directly — ranking still matters, but the destination is now an AI answer rather than a click.
Real-time web search. Google AI Overviews, Google AI Mode, and ChatGPT with search conduct live queries and synthesize results on the fly. The AI reads across multiple sources and generates a response. Content that is structured, direct, and answers the specific question clearly is favored. A page that buries its answer in five paragraphs of context loses to a page that leads with the answer.
What each mechanism means for your brand
| Mechanism | What determines inclusion | What you can influence | Timeline |
|---|---|---|---|
| Training data | Volume and authority of third-party coverage | Press, reviews, analyst mentions, forum presence | Slow — tied to model retraining |
| RAG / retrieval | Search ranking for relevant queries | Content quality, SEO, link authority | Medium — weeks to months |
| Real-time search | Ranking plus content clarity for the exact question | Same as RAG, plus direct question-answering structure | Medium — similar to SEO |
Why brands disappear from AI answers
Most brands are not excluded from AI answers. They are simply absent because the conditions for inclusion were never met. Four patterns account for most cases.
Thin web presence. A brand with a polished website but almost no third-party coverage — no reviews, no press mentions, no analyst notes — is largely invisible to the training corpus.
Inconsistent descriptions across sources. If your brand is positioned as enterprise on your site, SMB on a review platform, and mid-market in a third-party article, the AI reflects that disagreement with hedged, uncertain language.
No third-party corroboration. A claim that appears only on your own site carries far less weight than the same claim appearing independently in multiple sources. Third-party corroboration is the currency of training-data authority.
Content that does not answer buyer questions. Retrieval pulls content that answers the specific question asked. If your content is structured around features and announcements rather than buyer questions, it is less likely to be selected.
Frequently asked questions
Does my website content affect what AI says about me? Yes, indirectly. Your site contributes to the training corpus and influences ranking, which affects retrieval. But third-party content about your brand typically carries more weight than self-authored content in both training data and retrieval contexts.
What happens after an AI model's training cutoff? Training data is frozen at the cutoff. Retrieval-based systems (Perplexity, ChatGPT with search, Google AI Overviews) pull live content and can reflect new material relatively quickly — which is why RAG-focused surfaces often show fresher brand information than chat-only models.
Why does ChatGPT describe my brand differently at different times? Usually because different query phrasings retrieve different documents, which generate different answers. Persistent inconsistency points to conflicting source material — not model randomness.
This is the second post in a three-part series. Start with AI Visibility: What It Is and Why It Matters Now for the foundational case. Continue with How to Improve Your Brand's AI Visibility for the action framework. To see how AI assistants currently describe your brand, request an AI brand audit.
Pavan is a co-founder of Markiqo, an AI brand intelligence platform that measures how ChatGPT, Claude, Gemini, Perplexity, and Google AI Overview describe and rank brands. Last updated May 2026.
Continue reading
What Is llms.txt and Why Your Website Needs One in 2026
llms.txt is a simple markdown file that tells AI crawlers exactly what your brand does, which pages matter, and how to represent you accurately. Here is what it is and how to create one in minutes.
Read postAEOGoogle’s "Personal Intelligence" is Live. Is Your Brand Recommendable?
Gemini can now read secure calendar events, emails, and photos to answer search queries. Here is what this means for your brand's AI search visibility.
Read postWant to see how AI describes your brand?
Get a report with your top narrative gaps and prioritized fixes.
Get Started